consulting@sinokap.com
https://it-support-china.com/
2025 年末,全球互联网在短短三周内两次遭遇大规模中断,背后都指向同一个关键基础设施提供商——Cloudflare。
从 11 月 18 日持续数小时的全球性访问异常,到 12 月 5 日早间约 25 分钟的大面积 HTTP 500 错误,这两起事件虽然触发原因不同,却共同揭示了一个现实问题:现代互联网高度集中化的架构,正在放大单点失误的影响范围。
1️⃣ 11 月 18 日:配置文件异常,引发全球链式崩溃
2025 年 11 月 18 日 11:20 UTC 起,ChatGPT、X(原 Twitter)、Spotify、Canva 等大量跨国服务几乎同时无法访问,甚至连网络监测平台 Downdetector 本身也出现异常。
Cloudflare 随后确认:这并非网络攻击,而是一次内部配置文件错误导致的系统性故障。
事故源头来自其 Bot Management 系统中的一个关键特征文件(feature file):
内部数据库权限变更后,开始异常输出大量重复数据
特征文件体积迅速膨胀
文件被自动同步至全球边缘节点
超出系统可处理上限后,大量节点同时失效
结果是:代理、CDN、WAF、零信任访问等核心服务在全球范围内同时受到影响,用户普遍遇到“连接失败”“访问超时”。
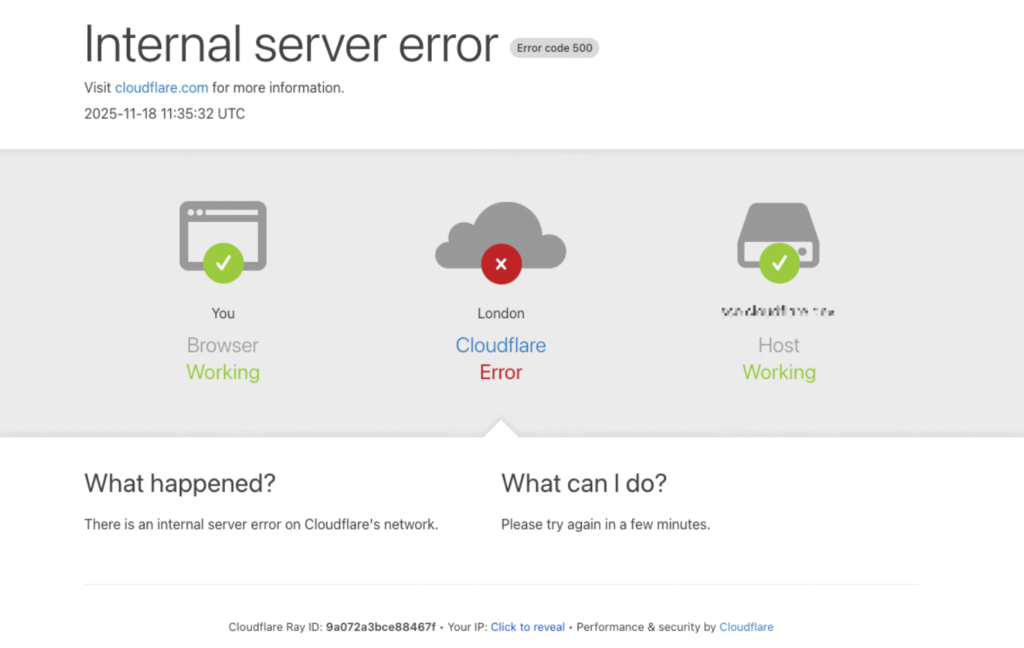
2️⃣ 12 月 5 日:系统更新触发旧代码缺陷
2025 年 12 月 5 日早晨,Cloudflare 再次发生故障,持续约 25 分钟。大量网站返回 HTTP 500 错误,企业官网、App、API 接口均受到影响。
这次事故的直接原因,是一次针对安全漏洞的系统修补。在更新过程中,触发了隐藏多年的旧代码缺陷,导致请求无法被正常处理。
同样需要强调的是:这起事件也不是外部攻击,而是典型的“修 bug 时撞到另一个 bug”。
Cloudflare 在现代互联网中承担的角色,早已不只是传统意义上的 CDN,还包括:
DNS 解析
CDN 加速
WAF 应用防火墙
反向代理
Bot 管理
零信任访问控制
边缘计算服务
当一家云服务商同时承载多个关键基础能力时,任何一个环节出现问题,都可能通过自动化系统被迅速放大,并在全球范围内同步传播。
这正是两次事件的共同特征。
在 Cloudflare 故障期间,不论企业规模大小,只要依赖相关服务,都可能出现:
官网或业务系统无法访问
App 内容加载失败
登录与身份验证异常
API 请求中断
这些问题往往直接带来:
交易失败
用户流失
客户投诉激增
品牌信任受损
更严重的是,不少企业在第一时间误判为“自身 IT 系统故障”,浪费了宝贵的应急响应时间。
两次事件共同揭示了企业 IT 架构中长期被忽视的几个问题:
即便是全球级云服务商,也无法保证绝对稳定
过度依赖单一供应商,会迅速演变为业务瓶颈
监控与可观察性不足,使企业只能被动承受冲击
缺乏备份与灾备机制,可能造成不可挽回的损失
云服务带来效率与成本优势,但并不会自动带来业务连续性。
真正成熟的 IT 架构,应当具备以下能力:
1. 避免单点依赖
DNS 采用多厂商方案(如主备切换)
CDN 使用多节点或多供应商策略
2. 建立可切换、可容灾的架构
关键系统具备备用访问路径
身份认证、邮件、核心业务支持本地 fallback
3. 强化变更管理与监控
自动化更新必须经过沙盒验证
关键变更具备回滚机制与实时告警
4. 提前规划第三方服务故障预案
明确上游服务中断时的应急流程
建立清晰的对内、对外沟通机制
Cloudflare 的两次故障再次提醒企业:风险并不只来自攻击者,也可能来自一次配置变更或一次例行更新。
在高度云化的时代,真正决定业务韧性的,不是使用了哪一家云服务商,而是——是否提前为“云不可用”这种情况做好了准备。
正因如此,Sinokap在实际项目中,始终从业务连续性出发,协助企业评估现有 IT 架构中的单点依赖风险,并通过多路径冗余、灾备设计与持续评估机制,帮助企业在突发事件中将业务影响控制在最小范围内。
Call Us, Write Us, Or Knock On Our Door. We are here to help. Thanks for contacting us!